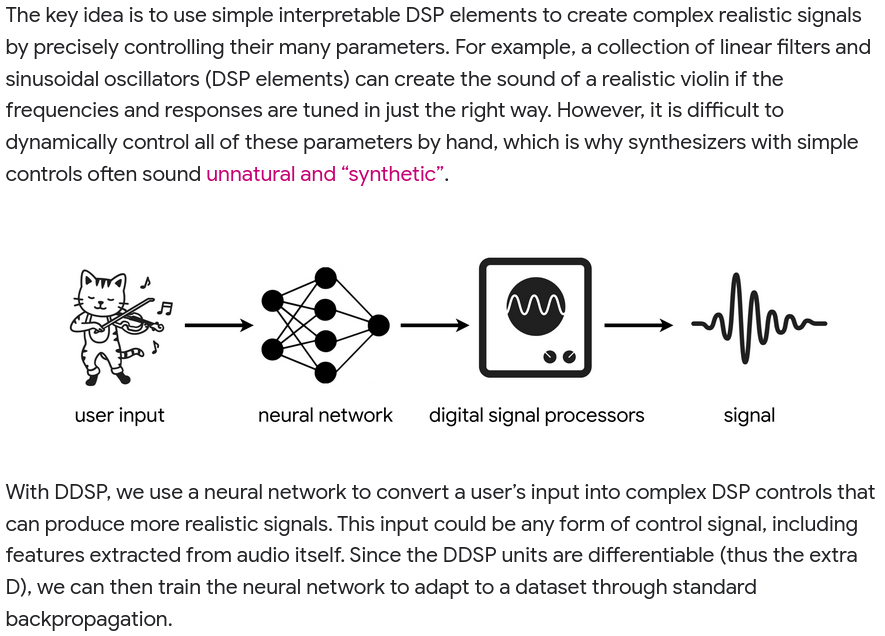
Thanks to the successes of deep learning, it is now popular to throw deep neural networks at an entire problem. These approaches are called end-to-end — it's neurons all the way down. End-to-end approaches have been applied to speech recognition and to speech synthesis On the one hand, these end-to-end systems have proven just how powerful deep neural networks can be. On the other hand, these systems can sometimes be both suboptimal, and wasteful in terms of resources. For example, some approaches to noise suppression use layers with thousands of neurons — and tens of millions of weights — to perform noise suppression. The drawback is not only the computational cost of running the network, but also the size of the model itself because your library is now a thousand lines of code along with tens of megabytes (if not more) worth of neuron weights.This is different from the primary rationale presented by the authors of Magenta DDSP[3],[4] in presenting their library:
Neural networks (such as WaveNet or GANSynth) are often black boxes. They can adapt to different datasets but often overfit details of the dataset and are difficult to interpret.These arguments aren't mutually exclusive - an overly large or computationally complex model is probably also one that is a black box, or difficult to understand.
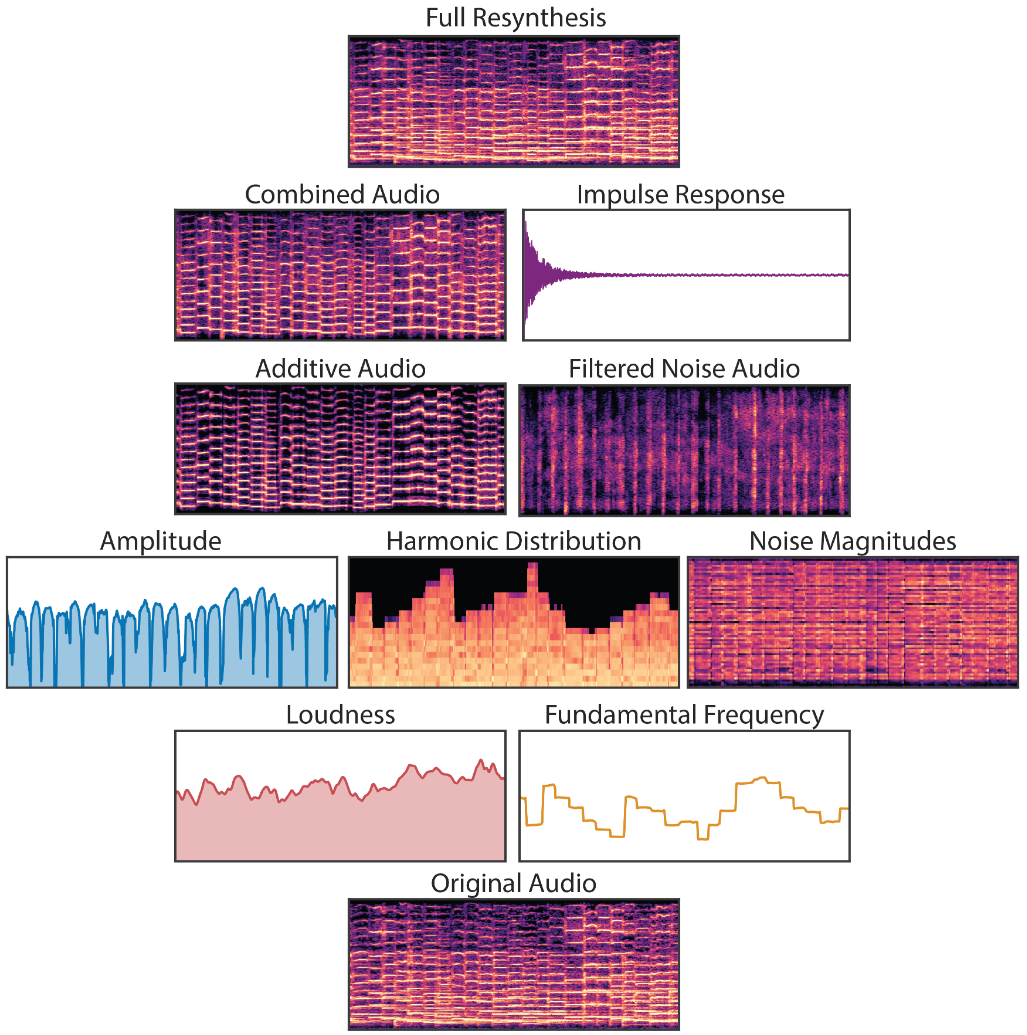
The bias of the natural world is to vibrate. Second-order partial differential equations do a surprisingly good job of approximating the dynamics of many materials and media, with physical perturbations leading to harmonic oscillations (Smith, 2010). Accordingly, human hearing has evolved to be highly sensitive to phase-coherent oscillation, decomposing audio into spectrotemporal responses through the resonant properties of the basilar membrane and tonotopic mappings into the auditory cortex (Moerel et al., 2012; Chi et al., 2005; Theunissen & Elie, 2014). However, neural synthesis models often do not exploit these same biases for generation and perception.

strided convolution models–such as SING (Defossez et al., 2018), MCNN (Arik et al., 2019), and WaveGAN (Donahue et al., 2019)–generate waveforms directly with overlapping frames. Since audio oscillates at many frequencies, all with different periods from the fixed frame hop size, the model must precisely align waveforms between different frames and learn filters to cover all possible phase variations
Fourier-based models–such as Tacotron (Wang et al., 2017) and GANSynth (Engel et al., 2019)–also suffer from the phase-alignment problem, as the Short-time Fourier Transform (STFT) is a representation over windowed wave packets. Additionally, they must contend with spectral leakage, where sinusoids at multiple neighboring frequencies and phases must be combined to represent a single sinusoid when Fourier basis frequencies do not perfectly match the audio
Autoregressive waveform models–such as WaveNet (Oord et al., 2016), SampleRNN (Mehri et al.,2016), and WaveRNN (Kalchbrenner et al., 2018)–avoid these issues by generating the waveform a single sample at a time. They are not constrained by the bias over generating wave packets and can express arbitrary waveforms. However, they require larger and more data-hungry networks, as they do not take advantage of a bias over oscillation. Furthermore, the use of teacher-forcing during training leads to exposure bias during generation, where errors with feedback can compound. It also makes them incompatible with perceptual losses such as spectral features (Defossez et al.,2018), pretrained models (Dosovitskiy & Brox, 2016), and discriminators (Engel et al., 2019). This adds further inefficiency to these models, as a waveform’s shape does not perfectly correspond to perception
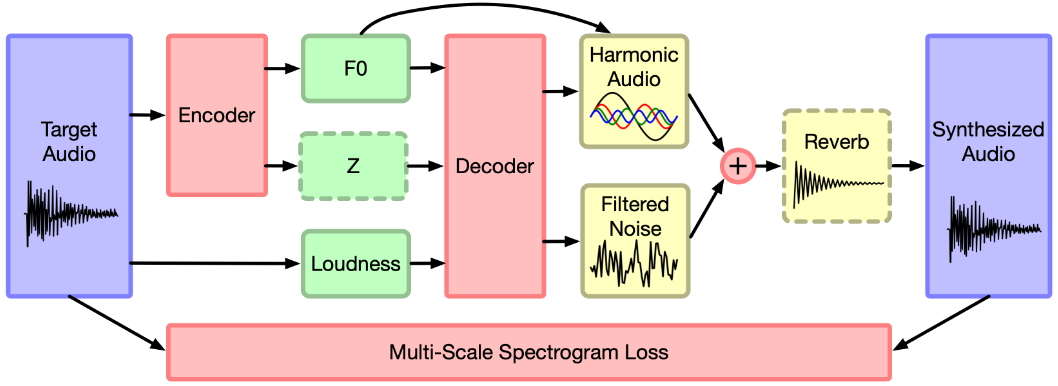
Using the MusOpen royalty free music library, we collected 13 minutes of expressive, solo violin performances.This is a huge reduction in the amount of training data required (e.g. 10 hours of piano performances were used to train WaveNet), by incorporating knowledge of the physical world and the human auditory system in the network.
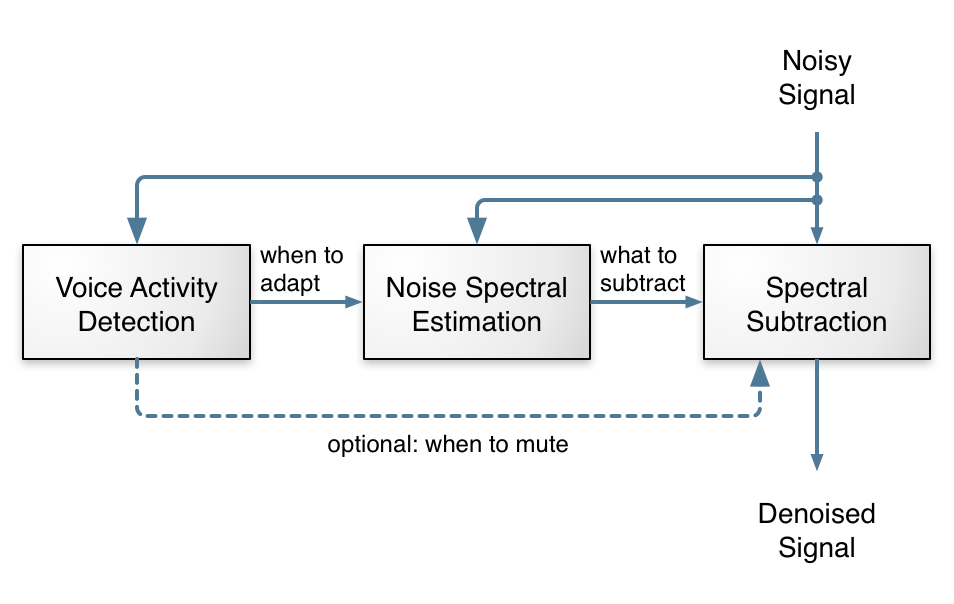
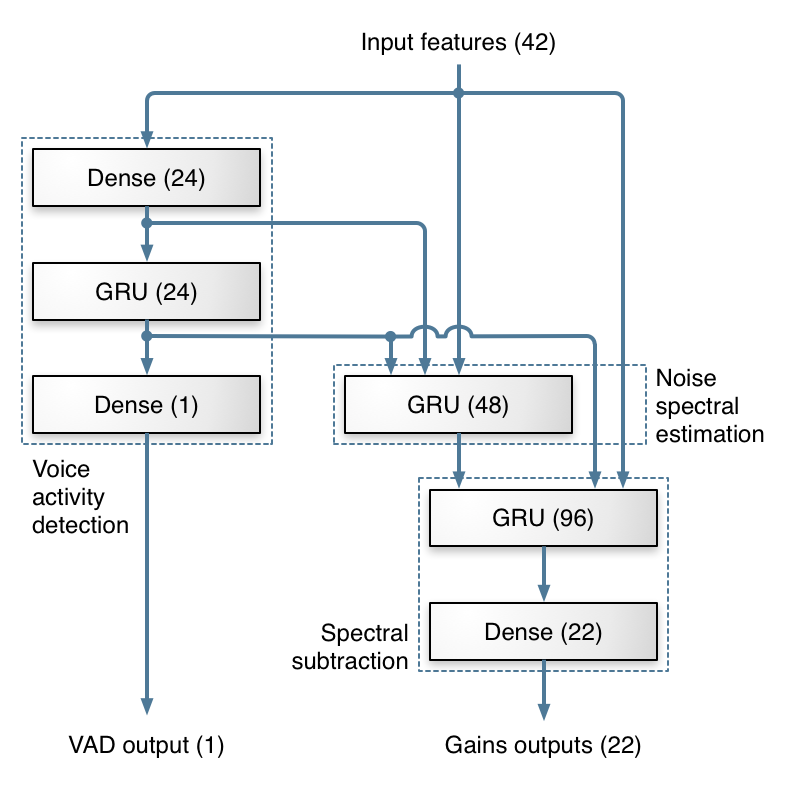
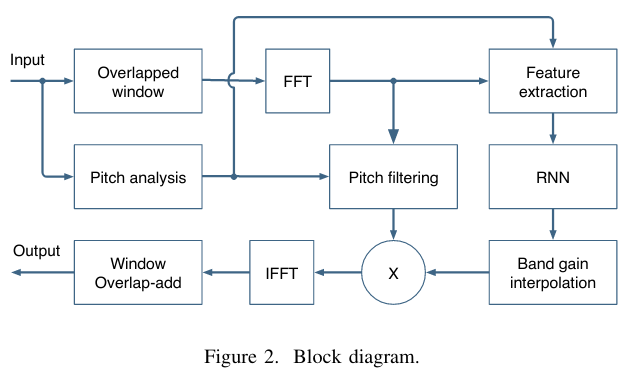
The signal-level block diagram for the system is shown in Fig. 2. The bulk of the suppression is performed on a low-resolution spectral envelope using gains computed from a recurrent neural network (RNN). Those gains are simply the square root of the ideal ratio mask (IRM). A finer suppression step attenuates the noise between pitch harmonics using a pitch comb filter.
training/rnn_train.py:
main_input = Input(shape=(None, 42), name='main_input')
tmp = Dense(24, activation='tanh', name='input_dense', kernel_constraint=constraint, bias_constraint=constraint)(main_input)
vad_gru = GRU(24, activation='tanh', recurrent_activation='sigmoid', return_sequences=True, name='vad_gru', kernel_regularizer=regularizers.l2(reg), recurrent_regularizer=regularizers.l2(reg), kernel_constraint=constraint, recurrent_constraint=constraint, bias_constraint=constraint)(tmp)
vad_output = Dense(1, activation='sigmoid', name='vad_output', kernel_constraint=constraint, bias_constraint=constraint)(vad_gru)
noise_input = keras.layers.concatenate([tmp, vad_gru, main_input])
noise_gru = GRU(48, activation='relu', recurrent_activation='sigmoid', return_sequences=True, name='noise_gru', kernel_regularizer=regularizers.l2(reg), recurrent_regularizer=regularizers.l2(reg), kernel_constraint=constraint, recurrent_constraint=constraint, bias_constraint=constraint)(noise_input)
denoise_input = keras.layers.concatenate([vad_gru, noise_gru, main_input])
denoise_gru = GRU(96, activation='tanh', recurrent_activation='sigmoid', return_sequences=True, name='denoise_gru', kernel_regularizer=regularizers.l2(reg), recurrent_regularizer=regularizers.l2(reg), kernel_constraint=constraint, recurrent_constraint=constraint, bias_constraint=constraint)(denoise_input)
denoise_output = Dense(22, activation='sigmoid', name='denoise_output', kernel_constraint=constraint, bias_constraint=constraint)(denoise_gru)
model = Model(inputs=main_input, outputs=[denoise_output, vad_output])
model.compile(loss=[mycost, my_crossentropy],
metrics=[msse],
optimizer='adam', loss_weights=[10, 0.5])
We can see most of the traits of the paper reproduced faithfully in the model code, which is very concise:
we apply a DCT on the log spectrum, which results in 22 Bark-frequency cepstral coefficients (BFCC). In addition to these, we also include the temporal derivative and the second temporal derivative of the first 6 BFCCs. We compute the DCT of the pitch correlation across frequency bands and include the first 6 coefficients in our set of features. At last, we include the pitch period as well as a spectral non-stationarity metric that can help in speech detection. In total we use 42 input features.
The design is based on the assumption that the three recurrent layers are each responsible for one of the basic components from Fig. 1. Of course, in practice the neural network is free to deviate from this assumption (and likely does to some extent).and their demo website[1]:
Of course, as is often the case with neural networks we have no actual proof that the network is using its layers as we intend, but the fact that the topology works better than others we tried makes it reasonable to think it is behaving as we designed it.
TRAINING-README:
(1) cd src ; ./compile.sh
(2) ./denoise_training signal.raw noise.raw count > training.f32
(note the matrix size and replace 500000 87 below)
(3) cd training ; ./bin2hdf5.py ../src/training.f32 500000 87 training.h5
(4) ./rnn_train.py
(5) ./dump_rnn.py weights.hdf5 ../src/rnn_data.c ../src/rnn_data.h
There is a matrix created which is then ingested by the rnn_train.py script to load the features of signal and noise for training the neural layers.
training/dump_rnn.py to dump the learned coefficients into C source and header files for the final RNNoise library, in src/rnn_data.c:
static const rnn_weight input_dense_weights[1008] = {
-15, 11, 11, 35, 37, 51, -56, -3,
-53, -55, 20, -7, -94, 2, -54, 23,
...
};
static const rnn_weight input_dense_bias[24] = {
5, 16, 9, 7, 0, -15, 11, -7,
12, 7, 10, -10, 6, -15, 11, 7,
-8, 11, -11, -21, -11, -19, -14, -14
};
static const DenseLayer input_dense = {
input_dense_bias,
input_dense_weights,
42, 24, ACTIVATION_TANH
};
static const rnn_weight vad_gru_weights[1728] = {
-35, -49, -33, -4, 40, -49, 24, -27,
28, -61, 57, -30, -65, -82, 19, 61,
-22, 42, 57, -61, 3, -18, -46, -31,
...
};
There are thousands of lines and weights, but this in fact reminds me of when I optimized BTrack (a pure-DSP beat tracking algorithm) on an Android phone, and precomputed some magic coefficient arrays. The point to the comparison is that the idea of arrays full of hardcoded coefficients is not unusual in the DSP realm.