Let's run some experiments with the SampleRNN implementation most successful for producing music - that of the dadabots. My earlier hestitation for using the dadabots code was how old the dependencies were. As such, it was slightly trickier to get up and running than the modern Tensorflow 2 PRiSM fork.
Python minor code tweaks
I vendored the dadabots_sampleRNN codebase[1] into the 1000sharks project to make a minor adjustment in the scripts[2].
diff --git a/models/two_tier/two_tier16k.py b/models/two_tier/two_tier16k.py
index 5a579c8..9f9d53f 100644
--- a/models/two_tier/two_tier16k.py
+++ b/models/two_tier/two_tier16k.py
@@ -505,10 +505,13 @@ def generate_and_save_samples(tag):
numpy.int32(t == FRAME_SIZE)
)
- samples[:, t] = sample_level_generate_fn(
- frame_level_outputs[:, t % FRAME_SIZE],
- samples[:, t-FRAME_SIZE:t],
- )
+ try:
+ samples[:, t] = sample_level_generate_fn(
+ frame_level_outputs[:, t % FRAME_SIZE],
+ samples[:, t-FRAME_SIZE:t],
+ )
+ except:
+ pass
total_time = time() - total_time
log = "{} samples of {} seconds length generated in {} seconds."
@@ -705,8 +708,9 @@ while True:
# 5. Generate and save samples (time consuming)
# If not successful, we still have the params to sample afterward
print "Sampling!",
+ print "skipping because it crashes!"
# Generate samples
- generate_and_save_samples(tag)
+ #generate_and_save_samples(tag)
print "Done!"
if total_iters-last_print_iters == PRINT_ITERS \
After several cycles of training, the program would crash with an index out of range error in the samples slicing code. After adding a try/catch, I noticed a second problem which is that the sample generation code (in between training steps) was using up all of my 32GB of RAM (not GPU vmem, but real system RAM). I ended up commenting out the generate_and_save_samples code. This means that while training, the model won't emit sample clips to allow one to listen to the quality of the training - but at least it prevented crashing.
Python setup
The dadabots SampleRNN installation instructions[3] are tailored to a Google Cloud Platform Ubuntu 16.04 setup with an NVIDIA V100 GPU. I adjusted the steps to work on my computer.
The full install steps for a functional dadabots SampleRNN (with notes) were as follows:
# we need python 2.7 for dadabots sampleRNN
# create a conda environment
$ conda create -n dadabots_SampleRNN python=2.7 anaconda
$ conda activate dadabots_SampleRNN
# we need Theano==1.0.0 - newer breaks
(dadabots_SampleRNN) $ conda install -c mila-udem -c mila-udem/label/pre theano==1.0.0 pygpu
# we need Lasagne (based on Theano) 0.2.dev1
# this command installs 0.2.dev1 correctly - suggested by https://github.com/imatge-upc/salgan/issues/29
(dadabots_SampleRNN) $ pip install --upgrade https://github.com/Lasagne/Lasagne/archive/master.zip
# we need to create a ~/.theanorc file with some cudnn details
# cudnn.h is installed on my system through Fedora repos, as mentioned previously
#
# nvcc requires an older GCC, 8.4, which I already had set up
$ cat ~/.theanorc
[dnn]
include_path = /usr/include/cuda
[global]
mode = FAST_RUN
device = cuda0
floatX = float32
[nvcc]
compiler_bindir = /home/sevagh/GCC-8.4.0/bin
# at this point, we have a working dadabots 2-tier SampleRNN model
# install some extra pip packages
(dadabots_SampleRNN) $ pip install graphviz pydot pydot-ng
Training data preparation
I ran the 2-tier dadabots SampleRNN on a Cannibal Corpse album, A Skeletal Domain:
Similarly to the 3-tier procedure, I downloaded the audio using youtube-dl, converted it to 16kHz mono with ffmpeg, placed the wav file in the required directory and ran the data prep script:
I had to modify their batch size from 128 (which would crash on GPU vmem OOM) to 32 to fit on the 8GB of GPU memory on my video card.
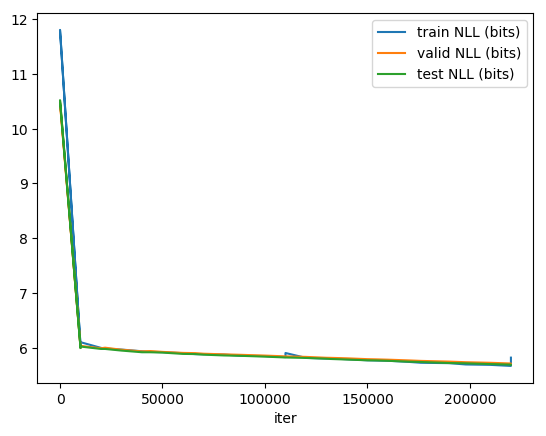
This ran for 10 epochs, or 90 hours of training (220,000 total iterations) when I decided to stop and verify the outputs. The saved model on-disk, 23GB in size, looks like this:
The results sound great - almost exactly like what the dadabots created, it sounds like unique (and random) compositions by the band Cannibal Corpse in the style of the album, A Skeletal Domain, that it was trained to overfit.
Checkpoint/training iteration 220,001:
In their raw form, the 200 disjoint 20-second output clips have varying musical content and need to be curated. This is a personal choice - the dadabots discuss the role of curation after generating 10 hours of music with their model[4], and I wanted to work on a curation script. I chose to work with 200x 20s wav files as my curation base.
Mini-conclusion
This sounds great and is the best performing music model, as promised by the dadabots in their paper[4]. Their paper describes the modifications and hyperparameters they made to SampleRNN, but the important hyperparameters are:
We use a 2-tier SampleRNN with 256 embedding size, 1024 dimensions, 5 layers, LSTM, 256 linear quantization levels, 16kHz or 32kHz sample rate, skip connections, and a 128 batch size, using weight normalization. The initial state h0 is randomized to generate more variety